【BR-013】ミニモミ。FUCKだぴょん! 4ばん 破解AI“瞎掰八说念”,这家公司要给大模子投喂好原料|家具不雅察

作家|黄楠【BR-013】ミニモミ。FUCKだぴょん! 4ばん
剪辑|袁斯来
大模子今天所展示出的坚毅能力,源于背后海量数据,为其注入了丰富的东说念主类常识。若是将大模子视为正在飞奔的科技列车,数据语料即曲直凡的“燃料”。其中,语料质料的提高对模子性能取得阶段性阻扰至关阻拦。
相关词一个现实情况是,高质料语料正在被急速消耗。国内大模子厂商所面对的语料空泛问题十分严峻。
以华文语料为例。中国工程院院士高文指出,现时公共通用的50亿大模子数据教悔集合,华文语料占比仅为1.3%,其数目和质料上同英文等其他话语比拟存在彰着不及。“熟睡”在论说、论文、报纸等文档内的开阔高价值语料数据,由于其复杂的版面结构,制约了大模子的教悔语料处理能力,无法被苟且领略并提真金不怕火。
处分华文数据不及和质料问题,处理种种化数据,照旧各厂商面对的一大挑战。
第4色官网为了匡助企业派遣数据局限问题,日前,合合信息在WAIC 2024上发布了用于大模子语料教悔的“加快器”家具——TextIn智能文档处理平台。
在教悔前期阶段,使用“加快器”文档领略引擎,破解竹帛、论文、研报等文档中的版面领略拒绝,为模子教悔与行使运送雪白的“燃料”;同期,“加快器”搭载了文本向量化模子,以处分大模子“已读乱回”的幻觉问题。
合合信息的想路是,从“真金不怕火丹”起源的燃料登程,通过圭臬化平台进行语料结构化,提高数据预教悔效力,匡助大模子厂商实现灵验的模子性能提高和迭代。
处理复杂语料合合信息这次发布的大模子“加快器”TextIn智能文档处理平台,由TextIn文档领略、TextIn Embedding(文本向量数据模子)以及OpenKIE三大器具构成。
现在,无线表、跨页表格、公式等复杂元素的处理,照旧大模子语料明显的“拦路虎”。
以银行常见的基金对账单托管业务为例,市面上基金公司繁密,各家企业的账单花样都不交流,加上复杂的表格呈现形式,要将数据从非结构化图文信息中抽取,并整理成模子教悔需要的形式,常常十分消耗东说念主力和时候。
失之豪厘、差之沉,一个单位格的聚拢问题,可能导致表格举座识别的甘休发生宏大差错;同期,表格的规复准确率,也径直影响了模子问答的甘休。
TextIn文档领略在文本、表格、图像等非结构化数据的推崇上,最快1.5秒就能完成百页长文档的领略;不仅速率快,同期还具备聚拢能力,不错智能规复文档的阅读司法。

大模子使用文档领略引擎之前(左)和之后(右)的甘休对比。甘休标明,使用后大模子具备了更快速、优秀的文档要素分析、表格内容识别能力。
面对多类型样本问题,合合信息在TextIn文档领略的算法阶段,就很防备图表数据教悔。现时,TextIn文档领略器具不错将柱状图、折线图、饼图、雷达图等十余种常见图表,以及纵脱模式文献 “规复”,并其拆解为Json(轻量级的数据交换模式)或Markdown(轻量级标注话语)模式。
经拆解后的数据语料明显易懂,不错让大模子更好地聚拢图表数据,进而学习生意研报和学术论文等专科文档中的论证逻辑。同期,在图表不深入具体数值的情况下,TextIn文档领略也不错仅依据坐标轴区间,蕾丝女同估算出具体数值。
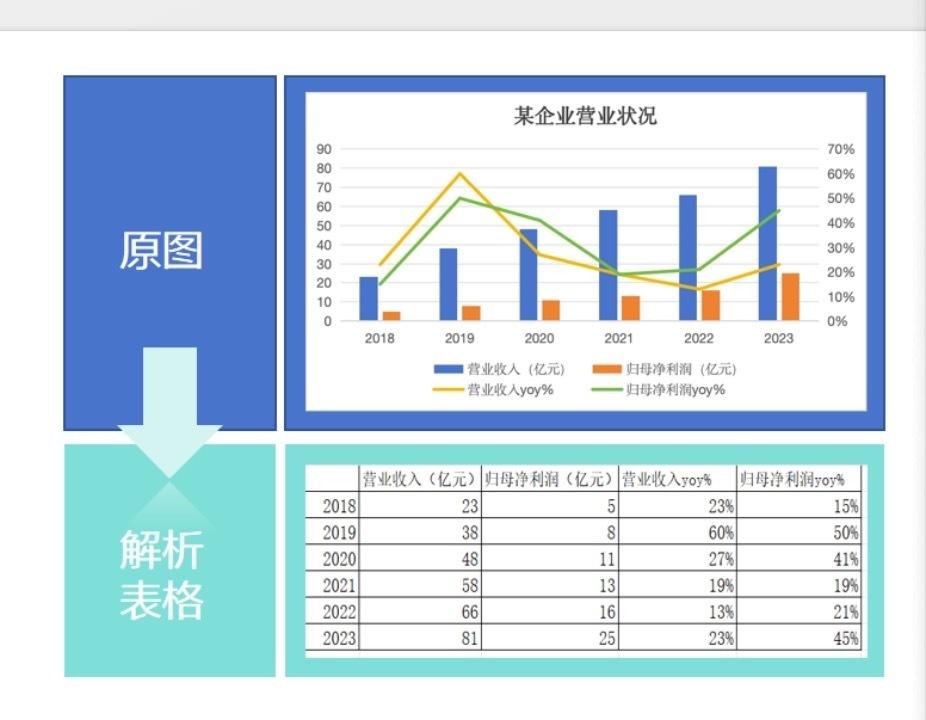
文档领略引擎基于坐标轴区间,对不深入具体数据的图表进行数值估算。
另一方面,大模子好像在通用问答中生成推崇很好,但就现阶段来看,面对专科畛域问题,大模子仍存在局限性,容易出现“一册庄重地瞎掰八说念”的幻觉,稍不珍贵,便可能带来严重的影响。
经测试,使用合合信息的TextIn Embedding模子(文本向量数据模子)后,能提开阔模子信息搜索和问答的质料、效力和准确性。
TextIn Embedding模子是一个acge_text_embedding模子(以下简称:acge模子)。就像“指南针”雷同,通过多量华文语料的深入学习,acge模子不错赶快对全文进行查找,找到指标信息定位,并将灵验的文本特征提真金不怕火出来,准确完要素类和聚类任务。
与其他开源模子比拟,acge模子体量较小,占用资源少,1024输入文本长度能骄慢绝大部分场景的需求。
固然大模子撑抓的token数目在抓续增多,令其具备了“短暂挂念”的能力,但仍会出现横祸性渐忘的问题。针对这一问题,acge模子引入了抓续学习教悔方式。
相较之下,acge模子撑抓可变输出维度,让企业能够笔据具体场景去合理分派资源,从而提高了模子系统的性能和体验。
以大模子厂商执行援用场景为例,卡通贴图在未引入向量数据库时,若是厂商接受的是散布式系统的开源有计算,其曲折在于,跟着语料增长到一定例模时,散布式存储很快就会碰到瓶颈;同期,每天上亿的数据处理量,按照传统单线才智处理方式速率有限。引入acge模子后,其文档的举座处理速率可得到显赫提高,同期在数据实足的情况下,还能拔除部分幻觉、多文档元素识别、版面分析等问题。
OpenKIE是一个可用于图像文档的信息抽取器具,其中包括了字段抽取、列表抽取和元素抽取三种模式。
客户只需创建好文档类型,建树需要提真金不怕火的字段并上传文献,OpenKIE就能自动抽取文档中所需信息,并径直行使、或导入到其他系统中使用。
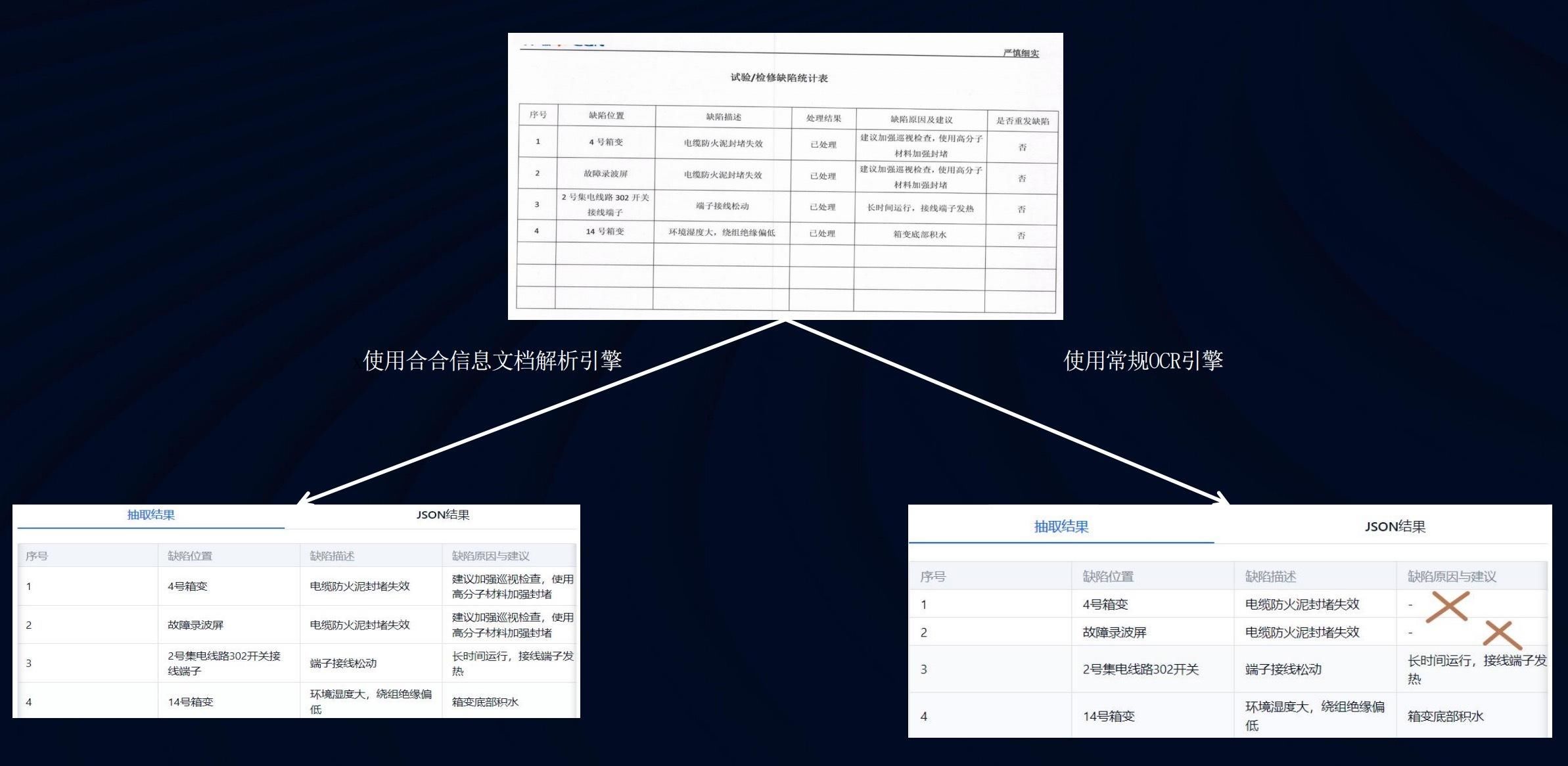
合合信息文档领略引擎与老例OCR引擎适用对比
比如在大模子文档处理场景中,合合信息与百川智能配合,共同破解困扰大模子产业已久的多文档元素识别、版面分析难题,将对百页文档的举座处理速率提高进步10倍。
合合信息智能转变职业部总司理唐琪告诉硬氪,现在,TextIn智能文档处理平台可秘密金融、医学、财经、媒体等47个场景,共3200余类文档;已被用于百川智能等多家头部大模子厂商的预教悔经由,同期也积累了小批量开辟者用户。
泛场景、通用的工程化能力就现在来看,险些大模子每一次能力提高,其预教悔数据的数目、语料质料、畛域类型等多维度都起到了关节性作用。
在数据处理方面,国内大部分厂商采取的有计算主要有两类:一类是交给提供基础行径工作的第三方公司,举例合合信息的TextIn智能文档处理平台、Amazon Textract文本提真金不怕火工作;另一类所以银行、券商等垂直赛说念企业为代表,在传统OCR算法基础上访佛教悔里面模子。
唐琪告诉硬氪,“从调研来看,企业采取供应商的圭臬无非就三个维度——快、稳、准。”
快,即文档领略引擎的速率要快;笔据合合信息测算, TextIn智能文档处理平台保抓在1.5秒内的领略时长,而现时市集上部分同类型器具的速率在其3-5倍。稳,指面向开阔量、复杂模式的语料,举例PDF文献、表单等,是否都能兼容并进行高准确度的领略使命。准,即能否将文档信息精确规复为表格。
现时,高质料、经梳理过的语料空泛是一大问题,“特别是华文数据更是稀缺,”唐琪说到。
国表里大模子数据集主要为英文,均源于许多开源数据集进行教悔,如Common Crawl、RedPajama、BooksCorpus、The Pile、ROOT等。这部分数据固然量多,但质料上却良莠不皆。一大优质的华文语料数据,熟睡在论说、论文、报纸等文档里。
从取得海量数据到高价值数据,预教悔阶段的语料处理十分关节。这意味着,动作一个平台型家具,向大模子厂商和开辟者“递铲子”,其基础的器具能力是否弥散塌实,关系到种子用户的购买意愿。
唐琪履历过这么一件事。有位从事二手毁坏贸易的商家手上积聚了多量小票,为了狡计利润,他每次需要东说念主工将售价减去原始价钱后,将最终甘休录入后台,悉数过程波及的公式狡计很复杂,包括数额差价、各项见识库存等问题,传统OCR模子无法行使。对方找到唐琪后,通过在加快器平台上调遣了小参数,很快需求得以处分了。
这仅仅一个细分场景中极为精采的小问题。在大模子时期,平台器具的本色形态,不同于单层的专有化部署逻辑,更强调面向泛场景、通用的工程化能力。
基于这一想路,合合信息在家具瞎想阶段提前作念了几件事。最初是场景前置,在未个性化阶段提前给模子补充多量优质的垂直畛域Know-how,比如金融、法律、老师等,留情特定行业中的开阔痛点,基于用户诉求在家具瞎想时提供处分有计算,进而提开阔模子加快器在中枢行使场景中推崇能力。
二是专注家具化,不单对客户提供通用场景的API,而是提供更多器具型家具,裁减行使门槛,作念到开箱即用,这对技艺资源较为薄弱的传统企业、中小创业公司或个东说念主开辟者来说特别友好。
大模子变革的波澜里,以数据为中心,成为行业东说念主士从事大模子研发和行使的共鸣。具体到履行层面,大模子上游阶段在文本领略、逻辑版面、文档问答等方面,仍有好多的提高使命不错作念。
畴前,合合信息将重心对准金融、医疗等行业推出垂直畛域家具,同期面向开辟者鼓动内测野心【BR-013】ミニモミ。FUCKだぴょん! 4ばん,吸纳更多用户参与到家具共创和优化中去。